Containerizing R Applications
When something is developed in R to be made available for general consumption it may not be an option to require an R runtime.
This post is about two things:
- How to pack an R application in a container and expose the functionality.
- How to automate the building of this container in Azure DevOps.
Exposing an R application
In the spirit of “services” I think the plumber package is fantastic tool to expose the functionality of an R package through a REST API.
Plumber’s documentation is good so I won’t go through a lot of introduction here.
One thing I want to mention is how I prefer to make a Plumber app, which is the so-called “programmatic usage” in the documentation.
In particular when debugging the app I use something like the following.
r <- plumber::plumber$new()
r$handle(
methods = "GET",
path = "/myendpoint",
handler = function(req, res) {
browser()
<my magic code>
return(res)
}
)
r$run(host = "127.0.0.0", port = 80)
Sourcing the file with the code exposes the endpoint http://127.0.0.0/myendpoint that can be called with e.g. the httr package.
When having both the request and response I find it easier to see what is actually available.
Async apps
In one scenario I have used the Plumber app as the starting point for a chain of actions.
The caller of the REST API needs a return code to be notified that the R calculation has started (or not started), but the consumer of the results are elsewhere.
Furthermore, the REST API should remain responsive at all times.
This will not happen with an app like above, where the calculation blocks the R process and thereby the response to the caller and the availability of the API.
To handle this I use the future package and the promises package.
The packages are well documented in the documentation for the promises package and a nice introduction is Joe Cheng’s talk at rstudio::conf 2018.
I end up with an app like this:
library(future)
library(promises)
plan(multisession)
r <- plumber::plumber$new()
r$handle(
methods = "GET",
path = "/myendpoint",
handler = function(req, res) {
future(myfunction(req$...)) %>%
then(
onFulfilled = function(value) {
<do something>
},
onRejected = function(err) {
<do something else>
}
)
return(res)
}
)
r$run(host = "127.0.0.0", port = 80)
In this setup the future call executes myfunction in a new process (with this plan) and the app moves on to return.
Depending on whether myfunction succeeds or fails then executes either onFulfilled or onRejected.
This works well if the computer running the app has enough resources to run the new processes on an idle core.
However, when packing such an app in a container and running it in a container service with limited resources I have seen that the new process consuming all resources thereby not allowing the app to return a response.
My solution to this is inspired by Python’s global interpreter lock, where the executing thread changes when I/O happens:
The first thing I do in myfunction is to write something to a “random” file:
cat(<message>, file = tempfile())
I do not care about the tempfile since the container will be closed at some point.
Plumber in a container
I use Plumber to expose the functionality of R packages.
I put the Plumber app in the inst folder of my package to make sure it is available in the installed package as well.
The app can then be started with
source(system.file('app.R', package = 'mypackage'))
I build Docker images based on my own images r-base and r-minimal.
I use a multi-stage build to install the package with r-base and copy them to r-minimal to be run.
The part that takes time when installing an R package on Linux is the compilation of the C++ code that is part of many popular packages.
But the dependencies of my package are often much more stable than the package itself.
Therefore the build time of the image can be reduced by first installing the dependencies based on just my package’s DESCRIPTION file and caching this image layer.
This caching trick is not applicable if the build computer does not cache the layers or if the DESCRIPTION is updated often.
ARG R_VERSION
ARG REGISTRY
FROM ${REGISTRY}/r-base:${R_VERSION} as deps
# First installing dependencies and then the package speeds build when there is a cache
COPY DESCRIPTION /tmp/package/
RUN Rscript -e "remotes::install_deps('/tmp/package')"
COPY --chown=shiny:shiny . /tmp/package/
RUN Rscript -e "remotes::install_local('/tmp/package')"
# --------------------------------------------------------------------
ARG R_VERSION
ARG REGISTRY
FROM ${REGISTRY}/r-minimal:${R_VERSION}
COPY --from=deps --chown=shiny:shiny /usr/local/lib/R/site-library/ /usr/local/lib/R/site-library/
EXPOSE 80
CMD ["R", "-e", "source(system.file('app.R', package = 'mypackage'))"]
Build container in Azure DevOps
My (work) R packages are under version control in Git and hosted on Azure DevOps.
I use the OneFlow Git branching model with one master branch and feature branches starting and ending in master.
Before merging new features into master they should be tested to ensure that code in the master branch “always works”.
Furthermore, each commit on master should result in a Docker image with the Plumber app.

I only merge feature branches into the master branch using pull requests – even if I am the only person contributing to the repository.
This ensures that new features are always tested and the subsequent build is handled automatically in a manner that can be tracked.
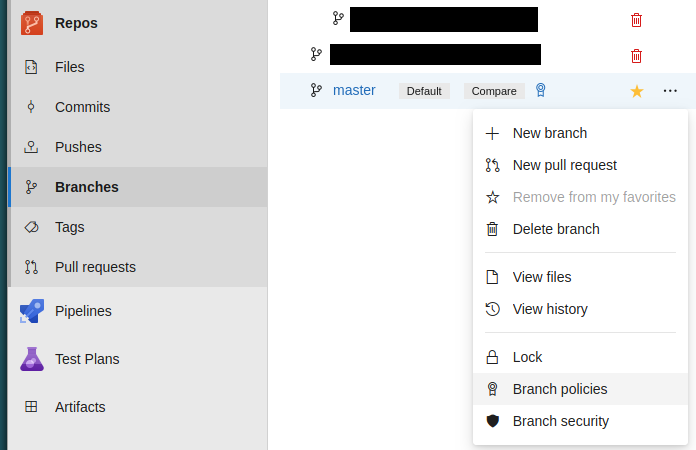
This is enforced in the “Branches” section of a repository by clicking the “overflow dots” and accessing the “Branch policies”.
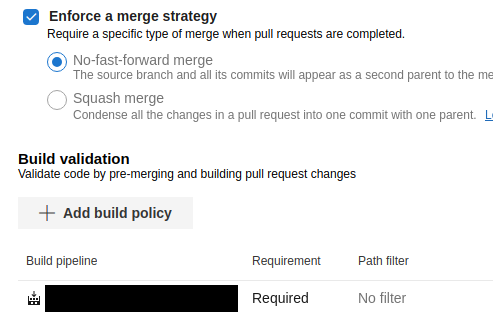
In the “Branch policies” I “Enforce a merge strategy” and as “Build validation” I add a test pipeline.
Workflow
I use two pipelines:
One for testing my code and one for building the container.
It may be tempting to just build the container as part of the test pipeline.
But imagine that pull requests needs to be reviewed before they can be completed.
Then there may be multiple updates to the pull requests before it is completed, each resulting in multiple built containers that should be discarded.
When the test pipeline runs Git it actually performs a pre-merge to test the code like it would be if the merge went through.

When the merge completes with the pull request the second build pipeline starts by enabling continuous integration on the “Triggers” tab in DevOps.
Build pipeline
My build pipeline has only two steps.

The “Get R and package version” task extracts two numbers from the package’s DESCRIPTION file:
The required version of R (just as in the test pipeline) and the version of the package.
RVERSION=`grep "R (.= [3-9].[0-9].[0-9])" DESCRIPTION | grep -o "[3-9].[0-9].[0-9]"`
echo "R version: $RVERSION"
echo "##vso[task.setvariable variable=RVersion]$RVERSION"
PACKAGEVERSION=`grep "^Version" DESCRIPTION | grep -o "[0-9].[0-9].[0-9]"`
echo "Package version: $PACKAGEVERSION"
echo "##vso[task.setvariable variable=PackageVersion]$PACKAGEVERSION"
The first and third echo statements are just for log.
The second and fourth echo statements set the extracted version numbers as variables to be used in the next task.
I always use semantic versioning with three numbers in the package versioning, which is what I extract for both the R version and the package version.
The “Build image” task builds the image directly in an Azure Container Registry using Azure CLI.
az account set --subscription "<Subscription ID>"
az acr build --file "Dockerfile.build" \
--build-arg REGISTRY="<registry>.azurecr.io" \
--build-arg R_VERSION=$(RVersion) \
--registry <registry> \
--resource-group "<resource group>" \
--image "myimage:$(PackageVersion)-$(Build.BuildNumber)" \
--image "myimage:$(PackageVersion)" \
.
I use “Subscription ID” instead of “Subscription” in the first line since the former is constant and the latter can be changed.
Both can be found on the “Overview” tab of the container registry:

Notice that I use two tags for the image as adviced in this post about best practices for tagging Docker images:
A “moving” tag with just the version of the package and a unique tag to ensure that we can always backtrace.
The format of the Build.BuildNumber can be set in the “Options” tab: